The Hugging Face Inference API allows you to call more than 200 modelsAI (LLM, image generation, embeddings, speech) via a single standardized API, without having to host the models yourself. In 2026, the service officially called Inference Providers and works as a router: you send your request to Hugging Face, which directs it to the right infrastructure partner (Cerebras, SambaNova, Together AI, DeepInfra, fal, Replicate...). You're paying for the provider's fee, no HF markup. See Official Documentation Inference Providers on huggingface.co.
📌 Essentials
- An API, hundreds of models: DeepSeek V4, Kimi K2.6, Llama, Qwen, GLM-5.1, FLUX.1, etc.
- Freetier: small monthly quota offered to all Hugging Face users connected.
- PRO Plan: 9 $/month — 2 $ Inference + 20× plus ZeroGPU quota.
- Pricing: pass-through of the providers, no HF margin (beyond the freetier).
- Compatible OpenAI : your code OpenAI walk with Hugging Face just changing the
base_url.
Contents: What is it? • How it works • Price and freetier • First call in Python • Use • Alternatives • FAQ
What is the Hugging Face Inference API?
Linference, in the vocabulary of machine learning, it is the action of turning a trained model to obtain a prediction. You give an LLM a quick, he returns you an answer — It's an inference. One API referenceSo it's just an API that allows you to do this remotely, without installing or running the model on your machine.
Hugging Face hosts the world's largest open-source model library (more than 1 million on the Hub). But running a 70 billion parameter model requires a 10,000 GPU € minimum. The Inference API solves this problem: you use the infrastructure of HF partners, you pay for use, and you do not manage any infra.
⚠️ Attention to vocabulary: do not confuse Inference API / Inference Providers (serverless, pay-as-you-go, multi-providers) with Inference Endpoints (Dedicated infrastructure, billed per hour, for stable production costs). Old name « Inference API (serverless) » has been rebranded « Inference Providers » in 2025 — Many articles still online use the old term.
How does the Inference API work in 2026?
The key concept of Inference Providers is routing. You don't call a GPU server directly. — You call the Hugging Face API, which dispatches your request to the most suitable partner.
- You choose a model on the Hub Hugging Face (e.g.
deepseek-ai/DeepSeek-V4-Pro). - You send a request with your Hugging Face token. There's no need for an account at every provider.
- HF route request to a partner provider hosting the model. More than 15 partners in May 2026: Cerebras, SambaNova, Together AI, DeepInfra, fal, Replicate, Public AI, Novita, Nebius, Hyperbolic, Groq, and others.
- The provider executes the model on its infra and sends the answer back to HF, which transmits it to you.
- You are billed by HF at the provider's rate, without markup.
You can choose the routing mode with a suffix on the model ID:
:fastest(default): provide the fastest in throughput.:cheapest: provide the cheapest at the exit token.:preferred: follow your order of preference configured in the settings.:nom_du_provider: you force a specific partner (e.g.:sambanova,:deepinfra).
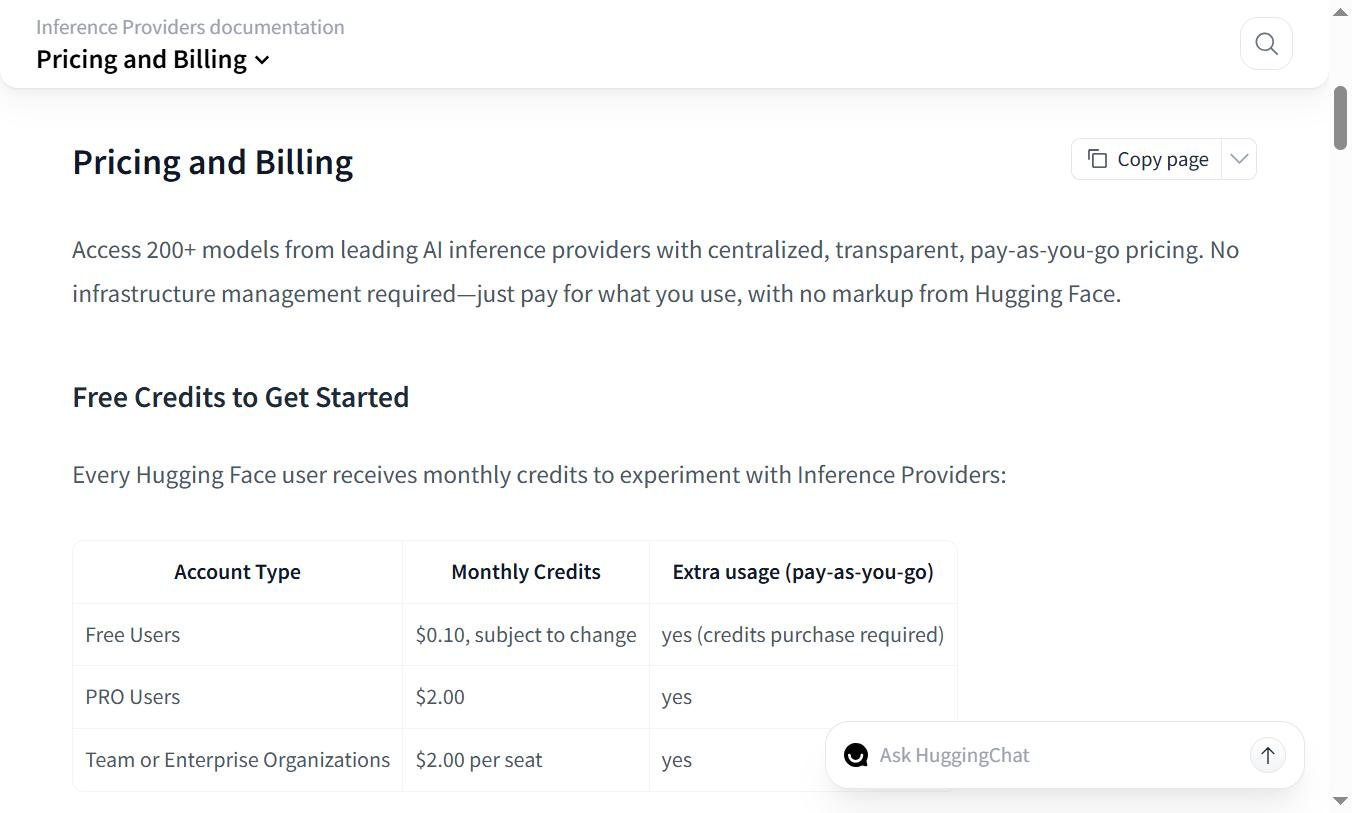
Price and free tier of the Hugging Face Inference API in 2026
The pricing holds in a few clear lines.
| Plan | Prices | Credits | Beyond |
|---|---|---|---|
| Free | 0 € | Small monthly quota offered | Pay-as-you-go |
| PRO | 9 $/month | 2 $ of credits + 20× ZeroGPU quota | Pay-as-you-go |
| Team | 20 $/month/seat | Pool shared | Pay-as-you-go |
| Enterprise | From 50 $/month | Custom + SLA | Pay-as-you-go |
Beyond the credits, you pay at the calculation time × hourly price of the hardware used. Practical example given by HF: a request to black-forest-labs/FLUX.1-dev which takes 10 seconds on a GPU at 0.00012 $/second costs you 0.0012 $. Less than one tenth of a cent per image. Full rates on the Hugging Face official pricing page.
For an LLM, you pay a million tokens — rates vary according to the routed provider and model. DeepSeek V4-Pro via DeepInfra runs around 0.30 $ per million tokens and 1 $ release in May 2026. Llama 3.3 70B costs much less. Always check the exact price on the model page in the Hub before going into production.
First call to the Hugging Face Inference API in Python
Three steps to call your first model.
1. Install SDK and connect
pip install huggingface_hub
huggingface-cli login
# Colle ton token (settings → Access Tokens, droits "Inference Providers")2. First call: conversation with an LLM
from huggingface_hub import InferenceClient
client = InferenceClient()
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro:cheapest",
messages=[
{"role": "user", "content": "Explique le RAG en 3 phrases."}
],
)
print(completion.choices[0].message.content)Suffix :cheapest asks HF to route to the cheapest provider for this model. You can put :fastest, :preferred or appoint a provider directly (:deepinfra, :sambanova, etc.).
3. Image Generation with FLUX
from huggingface_hub import InferenceClient
client = InferenceClient()
image = client.text_to_image(
"A cyberpunk cat reading a book in a Tokyo café, neon lights, cinematic",
model="black-forest-labs/FLUX.1-dev",
)
image.save("cat.png")You just coded a mini ai image generator in 6 lines. The same principle works for speech-to-text, text-to-speech, embeddings, translation, classification.
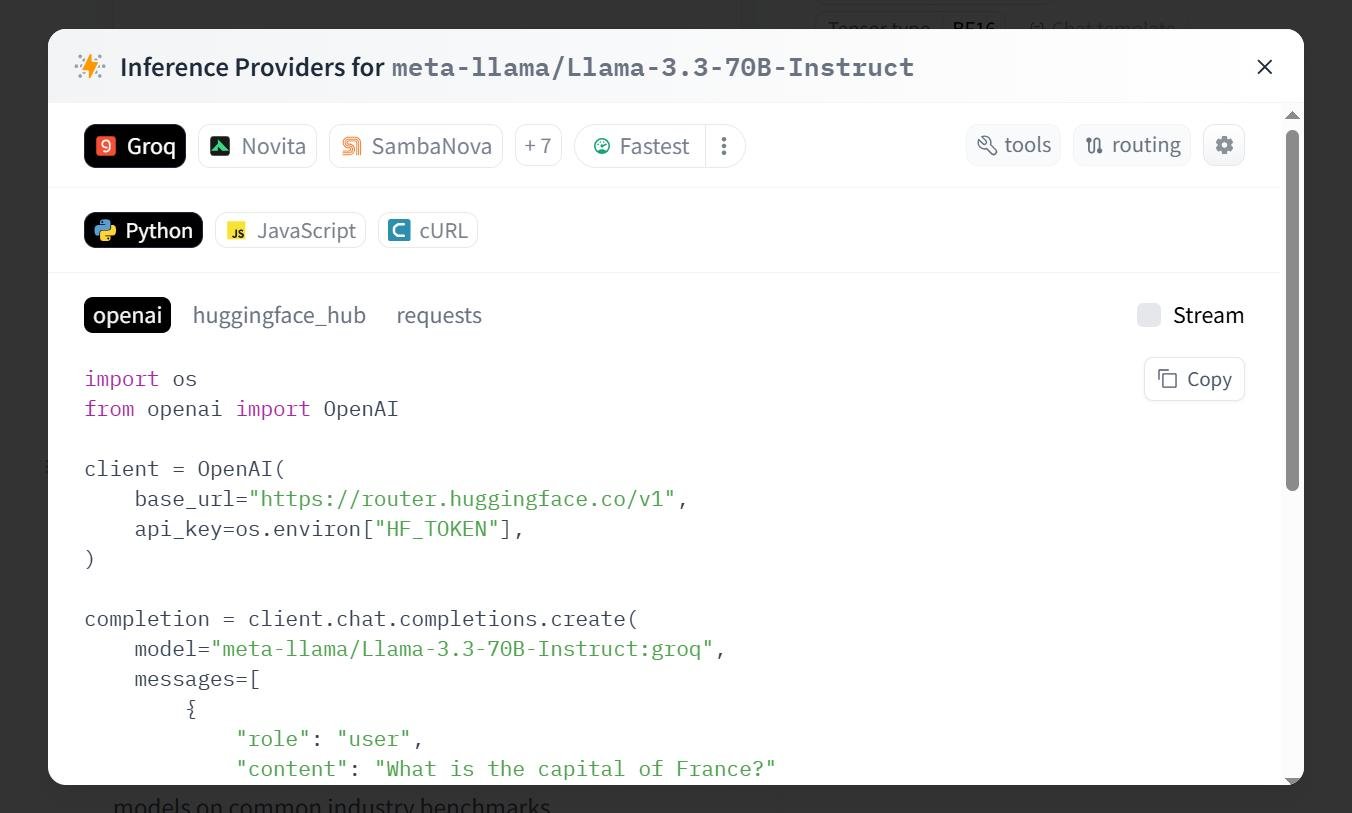
Compatibility OpenAI : one change
If your existing code uses SDK OpenAI, you can point to the HF router by just changing the base_url :
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key="hf_xxxx", # ton token Hugging Face
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[{"role": "user", "content": "Hello"}],
)
This compatibility covers only the complete cat. For text-to-image, embeddings or speech, use InferenceClient of the huggingface_hub.
What's the point?
- Prototype quickly an app AI without deploying infra. Test 5 different models by changing a name in the code.
- Compare open-source models on your own prompts before choosing which one to produce.
- Build an RAG app Combining a LLM (Llama, DeepSeek, Kimi) with an embeddings model, all via the same API.
- Content Generation : ai image generator via FLUX, synthetic voice, audio transcription.
- Niche Apps AI video : automatically transcribe subtitles, generate thumbnails, classify content — useful if you build a tool in the ecosystem video ai.
Alternatives to Hugging Face Inference API
- Direct API of providers : Together AI, fal, DeepInfra, Replicate, Cerebras. You sometimes earn a few cents a million tokens, but you lose the simplicity of the multi-provider.
- Official APIs for Publishers : OpenAI, Anthropic (Claude), Google (Gemini), Mistral AI. More expensive in general, but with proprietary models that HF does not offer (GPT-5, Claude Opus 4.7, Gemini 3.1 Pro).
- Self-accommodation with vLLM, Ollama or TGI on your GPU. Meaning for very high and stable loads, no sense for prototyping.
- Hugging Face Inference Endpoints : infrastructure dedicated to the hour, for prod charges where latency and predictability count more than pay-as-you-go.
💡 When to choose HF Inference Providers: If you want to test several open-source models quickly, if you want a single invoice, if you want to keep the choice between providers according to performance. Avoid if you use only one massively proprietary model (directvas at the publisher).
FAQ — Hugging Face Inference API
Is the Hugging Face API free of charge?
Partly. Every connected user receives a small monthly quota offered to experiment. Once the quota is consumed, it's pay-as-you-go at the provider's rate. PRO users (9 $/month) receive 2 $ Inference per month plus 20 ZeroGPU quota.
Is Hugging Face 100 percent free?
No, not 2026. The Hub remains free (browse, download, create basic CPU Spaces). But the Inference Providers, Spaces GPU (0.40 to 23.50) $/h), Inference Endpoints and extended private storage are paid. The freetier is enough to learn and experiment.
What difference between Inference API and Inference Endpoints?
Inference Providers (ex Inference API serverless): serverless, pay-as-you-go, multi-providers, ideal for prototypes and irregular volumes. Inference Endpoints: dedicated infrastructure billed per hour, for stable production costs.
Which models are available via the APIInference?
More than 200 models in May 2026: DeepSeek V4, Kimi K2.6, Llama 3.3, Qwen, GLM-5.1, Mistral Large 3, FLUX.1, Stable Diffusion XL, Whisper and many others. The list evolves every week.
Does Hugging Face put a margin on providers' prices?
No. HF passes the provider's tariff without markup. The HF margin is on PRO, Team, Enterprise and dedicated Inference Endpoints subscriptions.
Is an API still paid?
No. Many API have a freetier (Hugging Face, OpenAI, Anthropic with initial credits, Google Gemini). Pay-as-you-go remains the norm as soon as we exceed the freetier volumes.
🎯 To be retained
The Hugging Face Inference API (officially Inference Providers since 2025) is the fastest way to call open-source models in production without managing infrastructure. Freetier generous to start, PRO to 9 $/month to go further, pay-as-you-go at the price of the providers afterwards.
To start: create a token on huggingface.co, install huggingface hub, copy the example Python above, and make your first call in less than 5 minutes.


