
The Classification AI Move every month, and the one you read elsewhere is probably already out of date. In May 2026, Claude Opus 4.7 (Anthropic) dominated the coding and theagentic, GPT-5.4 (OpenAI) leading to math, and Gemini 3.1 Pro (Google) which remains unbeatable on multilingualism. On LMArena, these three are equally statistical at the top — and position #1 changes every week.
📌 Essentials
- General No. 1: Claude Opus 4.7, released on April 16, 2026.
- No. 1 math: GPT-5.4; Multilingual N°1/long context: Gemini 3.1 Pro.
- The real n°1 is not accessible: Claude Mythos Preview (Anthropic) remains locked for safety reasons.
- General Market: ChatGPT 64%, Gemini 21.5%, Claude ~2 % — But Claude dominates in B2B (70% of new deals enterprise).
- Never trust a single ranking: cross LMArena + a technical benchmark relevant to your use.
Contents: Top 10 May 2026 • LAI #1 in the world • Category classification • LMArena methodology • Choose a classification method • Models and energy • 7 typesAI • FAQ
The 10 modelsAI best performing in May 2026
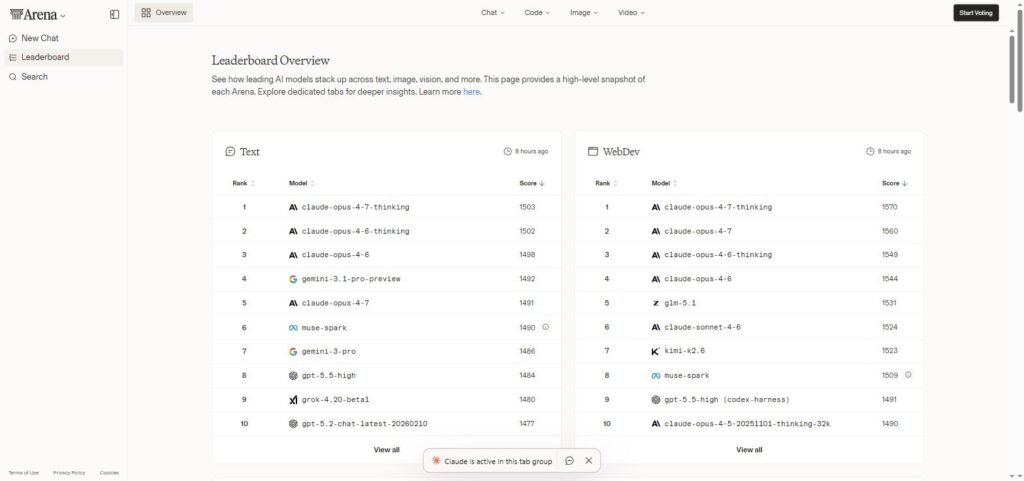
This top 10 crosses three sources: LMArena's Elo scores (6.1 million user votes as of May 6, 2026), the Artificial Analysis Intelligence Index v3 (10 aggregate benchmarks) and technical benchmarks — SWE-Bench Pro for code, GPQA Diamond for reasoning, AIME for math. See the real-time ranking on Imarena. a.
| # | Model | Publisher | Main Force |
|---|---|---|---|
| 1 | Claude Opus 4.7 | Anthropic | Coding agentic, knowledge work |
| 2 | GPT-5.4 | OpenAI | Maths, complex reasoning |
| 3 | Gemini 3.1 Pro | Multilingual, context 1M+ tokens | |
| 4 | Claude Opus 4.6 | Anthropic | Writing, narration (1518 Elo Writing) |
| 5 | Grok 4.1 Thinking | xAI | Real time data via X |
| 6 | GPT-5.2 Codex | OpenAI | Coding pure, leader Code Arena |
| 7 | DeepSeek V3 | DeepSeek | Perf ratio to unbeatable cost |
| 8 | Kimi K2.6 | Moonshot AI | Open-weights border (90.5% GPQA) |
| 9 | GLM-5 | Z.AI | Open-source enterprise-ready |
| 10 | Mistral Large 3 | Mistral AI | European Sovereignty (The Cat) |
⚠️ In particular: Anthropic confirmed the existence of Claude Mythos PreviewMore powerful than Opus 4.7. It remains reserved for a small circle of companies within the framework of Project Glasswing (cybersecurity). OpenAI referred to an internal model of the same calibre. The real world number 1 is therefore not on over-the-counter.
What is it?AI Number one in the world in 2026?

On most benchmarks coding and agentic, this is Claude Opus 4.7. Released on 16 April 2026 by Anthropic, he scored +13% on the internal benchmark (93 coding tasks) compared to Opus 4.6, and 64.3% on SWE-Bench Pro — the reference in realistic software engineering. But « Number 1 » Depends on the task.
- Coding agentic: Claude Opus 4.7
- Pure Coding (Code Arena): GPT-5.2 Codex holds crown since January 2026
- Math: GPT-5.4 (lead on AIME and closed benchmarks)
- Multilingual: Gemini 3.1 Pro (200+ languages, including underrepresented languages)
- Long context: Gemini 3.1 Pro and Claude Opus 4.7 (1M tokens, i.e. ~750,000 words)
- Long Writing and Narration: Claude Opus 4.6 (1518 Elo on LMArena Writing)
- Open source: Kimi K2.6 (90.5% GPQA, the best open-weight ratio available)
On LMArena Text in May 2026, the top 3 (Claude Opus 4.7, Gemini 3.1 Pro, GPT-5.4) stands in overlapping confidence intervals. It means no one is statistically. « better » the other two. Anyone who tells you « X is number 1 » Without specifying what half-truth tells you.
What are the top 5 AI Generalists?
If we talk about usage and public awareness, here is the quintet that dominates in May 2026:
- ChatGPT (OpenAI) — 900 million users per week, 64% of the global chatbot market.
- Gemini (Google) — 750 million monthly users, up sharply thanks to Android pre-installation. Market share increased from 5.7% to 21.5% in one year.
- Claude (Anthropic) — Only 18.9 million monthly web users, but 70% of new deals business according to Ramp. Anthropic raised $30 billion in February 2026 at a valuation of $380 billion.
- DeepSeek — 3.7% overall market share, but dominant in China (89%) and Central Asia.
- Grok (xAI) — 3.4%, natively integrated with X (ex-Twitter), with access to real time data.
What are the 3 AI Most used?
ChatGPT, Gemini, Claude. But « more used » does not mean the same in all three cases. ChatGPT reigns over the general public. Gemini explodes with Android. Claude dominates in B2B with a striking figure: Average of 34.7 minutes per daily session, the industry record according to Apptopia (Microsoft Copilot follows 27.2 minutes).
And then there is this figure that is often forgotten: 79% of companies that pay OpenAI Also pay Anthropic. The market is not zero-sum. Pros use several models as needed.
What AI is better than ChatGPT ?
None on all grounds. Many on specific grounds. This is where ChatGPT was beaten in May 2026:
- Code: Claude Opus 4.7 (64.3 % SWE-Bench Pro vs. ~58% for GPT-5).
- Write long: Claude Opus 4.6, leader on LMArena Writing and Creative Writing with a significant lead (~32 Elo on GPT-5.2 in Creative Writing).
- Real time web search with sources: Perplexity or Gemini (direct integration) Google Search).
- French and sovereignty: The Cat (Mistral). European hosting, GDPR compliant, free in standard version.
- Cost with equivalent performance: DeepSeek V3 and Kimi K2.6, 5 to 10× cheaper than GPT-5 for very close perfs on routine tasks.
ChatGPT remains the best generalist for a lambda user. Interface, memory, integrations, GPT Store, mobile version, voice — The ecosystem is in advance. If you only use one AI, this is probably the right choice by default. But « the right default choice » is not « the best on your task ».
The best models ofAI by category in May 2026
The overall ranking is misleading. Depending on your actual usage, the right model changes. Here's the picture by category.
AI text and conversation
Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro. Top 3 LMArena, a few points away from Elo. For a versatile daily use, ChatGPT remains the simplest. For long technical work or reasoning in several stages, Claude. For multilingual or web-based searches, Gemini.
AI image (ai image generator)
The LM Arena Text-to-Image classification of end 2025 placed TPM Image 1.5 in the lead (1264 Elo), followed by Gemini 3 Pro Image (1235) and Flux 2 (1168). The ranking has not moved radically since. A good one ai image generator chooses according to the intended rendering:
- Photorealism: GPT Image 1.5, Flow 2.
- Artistic and creative style: Midjourney v7 (excluding LMArena, but sector reference).
- Open-source customisable : Stable Distribution XL and its derivatives.
- Product/marketing integration: Gemini 3 Pro Image, available in Google Workspace.
AI video (video ai)
The segment video ai exploded in 2025-2026. Five tools dominate:
- Sora 2 (OpenAI) : photorealistic text-to-video, up to 60 seconds.
- Veo 3 (Google DeepMind): cinema quality, native synchronised audio.
- Runway Gen-4: reference post-production pro.
- Kling AI 2: Chinese leader, especially good on human faces.
- Deevid AI : tool practical for creators, paid plans from 19 $/month.
For a comparison detailed case-oriented marketing use, a comparison best AI software video 2026 testing 10.
AI face swap (face swap ai)
The face swap ai (sometimes written swap face ai) became a separate category. Three tools Get out of the lot:
- Vidnoz AI : free swap face up to 3/day, works on image and video, solid quality for social networks.
- Face: Pure mobile application, perfect for TikTok virality.
- DeepFaceLab: open-source, long learning curve but pro results.
AI voice and audio

ElevenLabs dominates voice quality and cloning — see our comparison ElevenLabs vs Speechify. Murf AI targets B2B (e-learning, voice-over corporate). For general music, Suno and Udio are the two references — they can generate a complete song with voices and instruments from a prompt.
AI creative text and rhymes
For rhyme in AI applied to rap, poetry or song lyrics, Claude Opus 4.7 and GPT-5.4 are the two models to test. On long fiction, Claude is unanimously preferred in community evaluations: he is better tuned, narrative voice and consistency of characters on entire chapters (1521 Elo in Creative Writing on LMArena, first in the category).
AI code
GPT-5.2 Codex, Claude Opus 4.7 and Gemini 3.1 Pro form the triad. On SWE-Bench Verified, Help Polyglot and the LMArena Arena Code, they are a few points apart. For agentic (Cursor, Claude Code, Cline), Opus 4.7 today has the best precision to cost ratio — That's also why Anthropic saw his share in the new deals enterprise climb so fast.
On what criteria is LMArena ranked?
LMArena (formerly LMSYS Chatbot Arena) is the most widely used evaluation by researchers and engineers AI. The principle is simple:
- You submit a prompt on lmarena.ai.
- Two models respond blindly — You don't know which one.
- You vote for the best answer.
- Votes feed an Elo score, like chess.
As of May 6, 2026, LMArena has accumulated 6.1 million votes out of 357 models. It's massive. But four structural biases are worth being known:
- Bias length: Longer answers earn more often, regardless of actual quality. A model that produces 500 words score better than a model that produces 200 words, even when the second is objectively better for the prompt.
- Style Bias: Well formatted answers (titles, bullets, fat) often beat the answers in pure prose. Visually formatted models leave with an advantage.
- Geographical variation: The same model does not rank the same according to whether the votes come mostly from the USA, India or Europe.
- Confidence intervals: the top 3 is very often at statistical equality. Position #1 displayed may be misleading.
For a pro decision (contract signing, choice of a model for your product), never settle for LMArena. Cross withArtificial Analysis Intelligence Index v3 which combines 10 benchmarks — MMLU-Pro, Humanity And especially do your own tests on your real quick. Data available on artificialanalysis. a.
How to choose the method of classifying models?
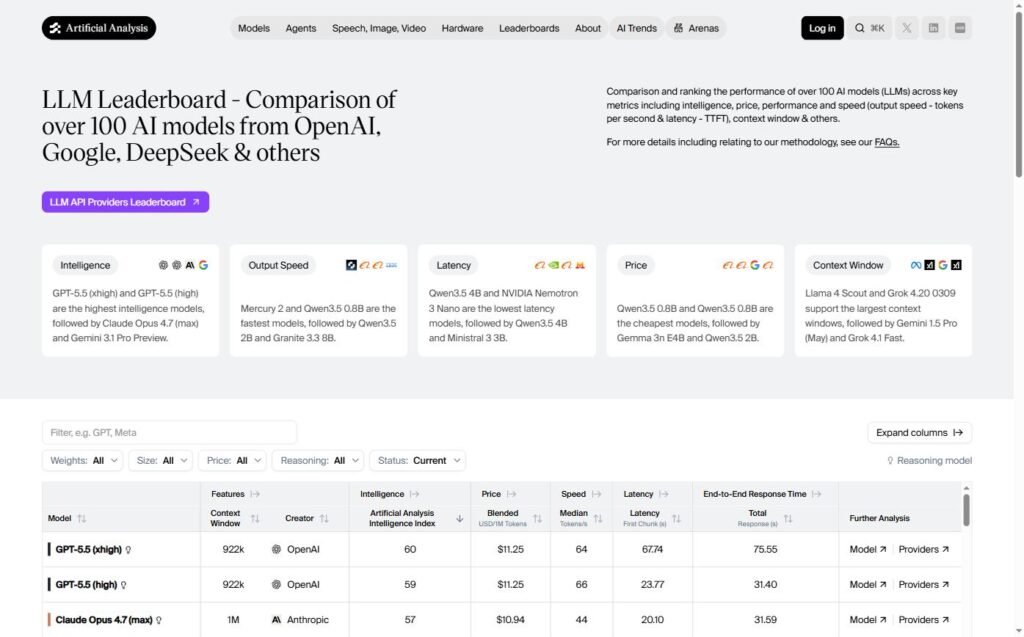
Three families of rankings coexist in 2026, and each has its limits.
- Human preference (LMArena): reflects the real experience of millions of users. Limit: length, style and geographic variance.
- Automated Benchmarks (MMLU, GPQA, SWE-Bench): Reproducible and accurate. Limit: « Bachotable » — publishers train their models to pass them.
- Composite indices (AAII v3, LLM Stats Score): aggregate several benchmarks for a more stable view. Limit: weighting is rarely transparent, and benchmarking choices guide the result.
💡 Our advice: Never trust a single ranking. For personal use, LMArena is enough to have an intuition. For pro use, cross at least LMArena + 1 technical benchmark relevant to your task (SWE-Bench if you code, GPQA if you make reasoning, AAII if you want a wide view). And do your tests on your own.
Are the most popular models energy efficient?
No. The top models in the ranking are the most greedy. A request on Claude Opus 4.7 consumes between 5 and 20× more than a request on Sonnet 4.6, depending on the complexity of the prompt and the mode of thought activated. The move to Opus 4.7 has even introduced a new tokenizer that can increase the actual cost from 0 to 35% per price request per token unchanged.
If energy efficiency matters to you (FinOps, CSR, simple common sense), look instead:
- Claude Sonnet 4.6 (Anthropic): 3 $/15 $ per million tokens, covers 90% of current uses.
- Gemini 2.5 Flash (Google) : ultra-fast, low footprint, free in standard version.
- DeepSeek V3: one of the best performance/cost ratios on the market, especially in API.
- Kimi K2.6: Open-weights leader at about 0.95 $ per million tokens.
Practical rule that can be seen in boxes that manage their costs AI seriously: a light model for 80% of tasks, a top model for 20% who really need it. This is exactly what the guides FinOps published since the launch of Opus 4.7.
What are the 10 AI the best known in the general public?
Classified by notoriety (research) Google, media presence, surveys used 2026), here is the top 10 general public :
- ChatGPT (OpenAI)
- Gemini (GoogleFormer Bard)
- Claude (Anthropic)
- Copilot (Microsoft)
- Grok (xAI)
- Perplexity
- DeepSeek
- The Cat (Mistral)
- Meta AI (integrated WhatsApp and Instagram)
- Midjourney (image)
Notoriety is not quality. Many people know ChatGPT without ever testing Claude. Others use AI yahoo (the Yahoo assistant launched in 2025) or Le Chat without realizing that they have free access to competitive models. Test multiple AI for two weeks often reveals unexpected preferences.
What are the 7 types ofAI ?
The classical computer typology distinguishes seven categories — four by capacity, three by range:
- AI reactive: no memory, responds only to the present. Historical example: Deep Blue from IBM chess.
- AI Limited memory: keeps a short context. The majority of current LMLs (ChatGPTClaude, Gemini) enter here.
- Mind Theory: able to model the mental states of others. Still looking.
- AI Self-consciousness: hypothetical. There is no such thing.
- ANI (Artifical Narrow Intelligence): specialized in a task. Siri, Netflix recommendations, spam filters.
- AGI (Artifical General Intelligence): human level on all cognitive tasks. Not reached officially, despite marketing ads.
- ASI (Artifical Super Intelligence): beyond humans. Theoretic.
In 2026, all commercial models — including the most powerful like Claude Opus 4.7 or Mythos Preview — are NIAs with limited memory. They are impressive on some tasks, but are neither general nor self-conscious.
FAQ — Classification AI 2026
How often the classification AI Does he change?
Weekly on LMArena. Monthly on closed benchmarks. Major releases (Opus 4.7 on April 16, 2026, GPT-5.4 earlier this year) beat the cards in a few days.
What model for free use?
ChatGPT (GPT-5 limited), Gemini (2.5 Flash without strict limits), Le Chat de Mistral (generous and hosted in Europe), Claude (limited but accessible). DeepSeek is free in chat and very cheap in API.
Should we pay for a premium model?
For occasional use, free versions largely cover 90% of the needs. For pro intensive use (coding, long writing, agentic), yes — Quality gap justifies 20 €/month. ChatGPT Plus, Claude Pro and Gemini Advanced are at this price.
Classification AI is it reliable to choose a tool pro?
As a benchmark, yes. As a final decision, no. Always do an internal test on your real quick before signing an annual contract. A procurement team that chooses its LLM on a LMArena capture on Tuesday can lose 15 to 20% of its bill over the year due to an already obsolete ranking on the following Tuesday.
What AI For French?
The Chat (Mistral) is designed for French and hosted in Europe. Claude Opus 4.7 and Gemini 3.1 Pro are also excellent in French. ChatGPT is correct but sometimes has turns that smell English translation.
🎯 Verdict: where to start
If you don't have time to test: ChatGPT for everyday life, Claude Opus 4.7 as soon as it becomes serious (code, long analysis, reasoning).
If you pay for your team: Claude Sonnet 4.6 in default model, Opus 4.7 out of 20% heavy tasks, Gemini 2.5 Flash for massive requests at forced cost.
If you are looking for sovereignty or a tight budget: Le Chat (Mistral) for French hosted in Europe, DeepSeek V3 for the unbeatable price/quality ratio.


