
Le classement IA bouge tous les mois, et celui que tu lis ailleurs est probablement déjà périmé. En mai 2026, c’est Claude Opus 4.7 (Anthropic) qui domine le coding et l’agentic, GPT-5.4 (OpenAI) qui mène sur les maths, et Gemini 3.1 Pro (Google) qui reste imbattable sur le multilingue. Sur LMArena, ces trois-là sont à égalité statistique au sommet — et la position n°1 change chaque semaine.
📌 L’essentiel à retenir
- N°1 général : Claude Opus 4.7, sorti le 16 avril 2026.
- N°1 maths : GPT-5.4 ; N°1 multilingue/contexte long : Gemini 3.1 Pro.
- Le vrai n°1 n’est pas accessible : Claude Mythos Preview (Anthropic) reste sous clé pour des raisons de sûreté.
- Marché grand public : ChatGPT 64 %, Gemini 21,5 %, Claude ~2 % — mais Claude domine en B2B (70 % des nouveaux deals enterprise).
- Ne te fie jamais à un seul classement : croise LMArena + un benchmark technique pertinent à ton usage.
Sommaire : Top 10 mai 2026 • L’IA n°1 au monde • Classement par catégorie • Méthodologie LMArena • Choisir une méthode de classement • Modèles et énergie • 7 types d’IA • FAQ
Les 10 modèles d’IA les plus performants en mai 2026
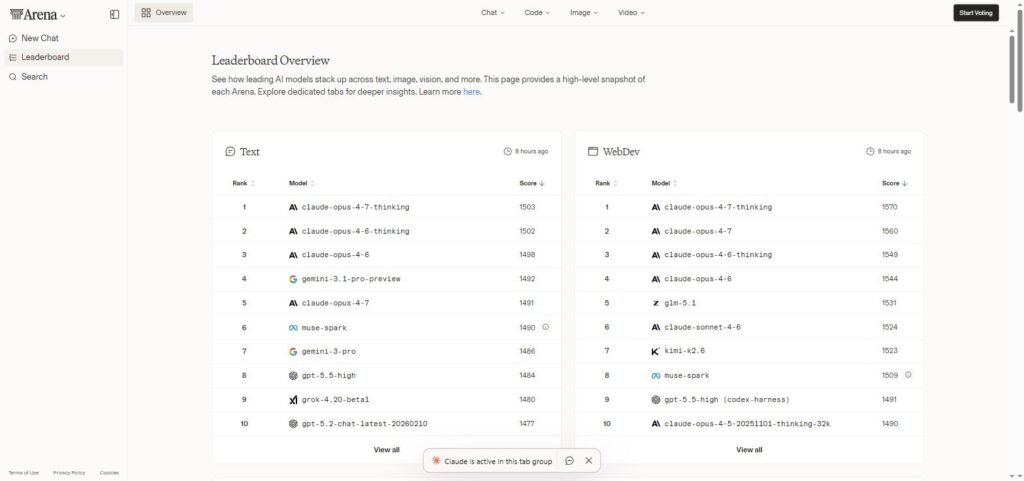
Ce top 10 croise trois sources : les scores Elo de LMArena (6,1 millions de votes utilisateurs au 6 mai 2026), l’Artificial Analysis Intelligence Index v3 (10 benchmarks agrégés) et les benchmarks techniques de référence — SWE-Bench Pro pour le code, GPQA Diamond pour le raisonnement, AIME pour les maths. Voir le classement en temps réel sur lmarena.ai.
| # | Modèle | Éditeur | Force principale |
|---|---|---|---|
| 1 | Claude Opus 4.7 | Anthropic | Coding agentic, knowledge work |
| 2 | GPT-5.4 | OpenAI | Maths, raisonnement complexe |
| 3 | Gemini 3.1 Pro | Multilingue, contexte 1M+ tokens | |
| 4 | Claude Opus 4.6 | Anthropic | Écriture, narration (1518 Elo Writing) |
| 5 | Grok 4.1 Thinking | xAI | Données temps réel via X |
| 6 | GPT-5.2 Codex | OpenAI | Coding pur, leader Code Arena |
| 7 | DeepSeek V3 | DeepSeek | Rapport perf/coût imbattable |
| 8 | Kimi K2.6 | Moonshot AI | Open-weights frontier (90,5 % GPQA) |
| 9 | GLM-5 | Z.AI | Open-source enterprise-ready |
| 10 | Mistral Large 3 | Mistral AI | Souveraineté européenne (Le Chat) |
⚠️ À savoir : Anthropic a confirmé l’existence de Claude Mythos Preview, plus puissant qu’Opus 4.7. Il reste réservé à un cercle restreint d’entreprises dans le cadre du Project Glasswing (cybersécurité). OpenAI a évoqué un modèle interne du même calibre. Le vrai numéro 1 mondial n’est donc pas en vente libre.
Quelle est l’IA numéro 1 au monde en 2026 ?

Sur la plupart des benchmarks coding et agentic, c’est Claude Opus 4.7. Sorti le 16 avril 2026 par Anthropic, il marque +13 % sur le benchmark interne (93 tâches de codage) par rapport à Opus 4.6, et 64,3 % sur SWE-Bench Pro — la référence en ingénierie logicielle réaliste. Mais « numéro 1 » dépend de la tâche.
- Coding agentic : Claude Opus 4.7
- Coding pur (Code Arena) : GPT-5.2 Codex tient la couronne depuis janvier 2026
- Maths : GPT-5.4 (lead sur AIME et benchmarks fermés)
- Multilingue : Gemini 3.1 Pro (200+ langues, dont des langues sous-représentées)
- Contexte long : Gemini 3.1 Pro et Claude Opus 4.7 (1M tokens, soit ~750 000 mots)
- Écriture longue et narration : Claude Opus 4.6 (1518 Elo sur LMArena Writing)
- Open-source : Kimi K2.6 (90,5 % GPQA, le meilleur ratio dispo en open-weights)
Sur LMArena Text en mai 2026, le top 3 (Claude Opus 4.7, Gemini 3.1 Pro, GPT-5.4) tient dans des intervalles de confiance qui se chevauchent. Ça veut dire qu’aucun n’est statistiquement « meilleur » que les deux autres. Toute personne qui te dit « X est numéro 1 » sans préciser sur quoi te raconte une demi-vérité.
Quelles sont les 5 principales IA généralistes ?
Si on parle d’usage et de notoriété grand public, voici le quintet qui domine en mai 2026 :
- ChatGPT (OpenAI) — 900 millions d’utilisateurs hebdomadaires, 64 % du marché chatbot mondial.
- Gemini (Google) — 750 millions d’utilisateurs mensuels, en forte hausse grâce à la pré-installation Android. Part de marché passée de 5,7 % à 21,5 % en un an.
- Claude (Anthropic) — seulement 18,9 millions d’utilisateurs web mensuels, mais 70 % des nouveaux deals enterprise selon Ramp. Anthropic a levé 30 milliards de dollars en février 2026 à une valorisation de 380 milliards.
- DeepSeek — 3,7 % de part de marché global, mais dominant en Chine (89 %) et en Asie centrale.
- Grok (xAI) — 3,4 %, intégré nativement à X (ex-Twitter), avec accès aux données temps réel.
Quelles sont les 3 IA les plus utilisées ?
ChatGPT, Gemini, Claude. Mais « plus utilisée » ne veut pas dire la même chose dans les trois cas. ChatGPT règne sur le grand public. Gemini explose grâce à Android. Claude domine en B2B avec un chiffre frappant : 34,7 minutes en moyenne par session quotidienne, le record de l’industrie selon Apptopia (Microsoft Copilot suit à 27,2 minutes).
Et puis il y a ce chiffre qu’on oublie souvent : 79 % des entreprises qui paient OpenAI paient aussi Anthropic. Le marché n’est pas zero-sum. Les pros utilisent plusieurs modèles selon le besoin du moment.
Quelle IA est mieux que ChatGPT ?
Aucune sur tous les terrains. Plusieurs sur des terrains précis. Voici où ChatGPT se fait battre en mai 2026 :
- Coder : Claude Opus 4.7 (64,3 % SWE-Bench Pro vs ~58 % pour GPT-5).
- Écrire long : Claude Opus 4.6, leader sur LMArena Writing et Creative Writing avec une avance significative (~32 Elo sur GPT-5.2 en Creative Writing).
- Recherche web temps réel avec sources : Perplexity (citations sourcées par défaut) ou Gemini (intégration directe Google Search).
- Français et souveraineté : Le Chat (Mistral). Hébergement européen, conforme RGPD, gratuit en version standard.
- Coût à performance équivalente : DeepSeek V3 et Kimi K2.6, 5 à 10× moins chers que GPT-5 pour des perfs très proches sur les tâches courantes.
ChatGPT reste le meilleur généraliste pour un utilisateur lambda. Interface, mémoire, intégrations, GPT Store, version mobile, voix — l’écosystème est en avance. Si tu n’utilises qu’une seule IA, c’est probablement le bon choix par défaut. Mais « le bon choix par défaut » n’est pas « le meilleur sur ta tâche ».
Les meilleurs modèles d’IA par catégorie en mai 2026
Le classement général est trompeur. Selon ton usage réel, le bon modèle change. Voici la photo par catégorie.
IA texte et conversation
Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro. Top 3 LMArena, à quelques points d’Elo près. Pour un usage quotidien polyvalent, ChatGPT reste le plus simple. Pour du travail technique long ou du raisonnement en plusieurs étapes, Claude. Pour du multilingue ou des recherches qui s’appuient sur le web, Gemini.
IA image (ai image generator)
Le classement LM Arena Text-to-Image de fin 2025 plaçait GPT Image 1.5 en tête (1264 Elo), suivi de Gemini 3 Pro Image (1235) et Flux 2 (1168). Le classement n’a pas bougé radicalement depuis. Un bon ai image generator se choisit selon le rendu visé :
- Photoréalisme : GPT Image 1.5, Flux 2.
- Style artistique et créatif : Midjourney v7 (hors LMArena, mais référence du secteur).
- Open-source customisable : Stable Diffusion XL et ses dérivés.
- Intégration produit/marketing : Gemini 3 Pro Image, dispo dans Google Workspace.
IA vidéo (video ai)
Le segment video ai a explosé en 2025-2026. Cinq outils dominent :
- Sora 2 (OpenAI) : text-to-video photoréaliste, jusqu’à 60 secondes.
- Veo 3 (Google DeepMind) : qualité cinéma, audio synchronisé natif.
- Runway Gen-4 : référence post-production pro.
- Kling AI 2 : leader chinois, particulièrement bon sur les visages humains.
- Deevid AI : outil pratique pour créateurs, plans payants à partir de 19 $/mois.
Pour un comparatif détaillé orienté cas d’usage marketing, on a publié un comparatif des meilleurs logiciels IA vidéo 2026 qui en teste 10.
IA face swap (face swap ai)
Le face swap ai (parfois écrit swap face ai) est devenu une catégorie à part. Trois outils sortent du lot :
- Vidnoz AI : face swap gratuit jusqu’à 3/jour, fonctionne sur image et vidéo, qualité solide pour les réseaux sociaux.
- Reface : application mobile pure, parfaite pour la viralité TikTok.
- DeepFaceLab : open-source, courbe d’apprentissage longue mais résultats pro.
IA voix et audio
ElevenLabs domine sur la qualité de voix et le clonage — voir notre comparatif ElevenLabs vs Speechify. Murf AI cible plutôt le B2B (e-learning, voix off corporate). Pour la musique générative, Suno et Udio sont les deux références — ils peuvent générer une chanson complète avec voix et instruments à partir d’un prompt.
IA texte créatif et rimes
Pour des rime en ia appliquées au rap, à la poésie ou aux paroles de chanson, Claude Opus 4.7 et GPT-5.4 sont les deux modèles à tester. Sur la fiction longue, Claude est unanimement préféré dans les évaluations communautaires : il tient mieux le ton, la voix narrative et la cohérence des personnages sur des chapitres entiers (1521 Elo en Creative Writing sur LMArena, premier de la catégorie).
IA code
GPT-5.2 Codex, Claude Opus 4.7 et Gemini 3.1 Pro forment la triade. Sur SWE-Bench Verified, Aider Polyglot et le Code Arena de LMArena, ils sont à quelques points d’écart. Pour de l’agentic (Cursor, Claude Code, Cline), Opus 4.7 a aujourd’hui le meilleur ratio précision/coût — c’est aussi pour ça qu’Anthropic a vu sa part dans les nouveaux deals enterprise grimper si vite.
Sur quels critères repose le classement de LMArena ?
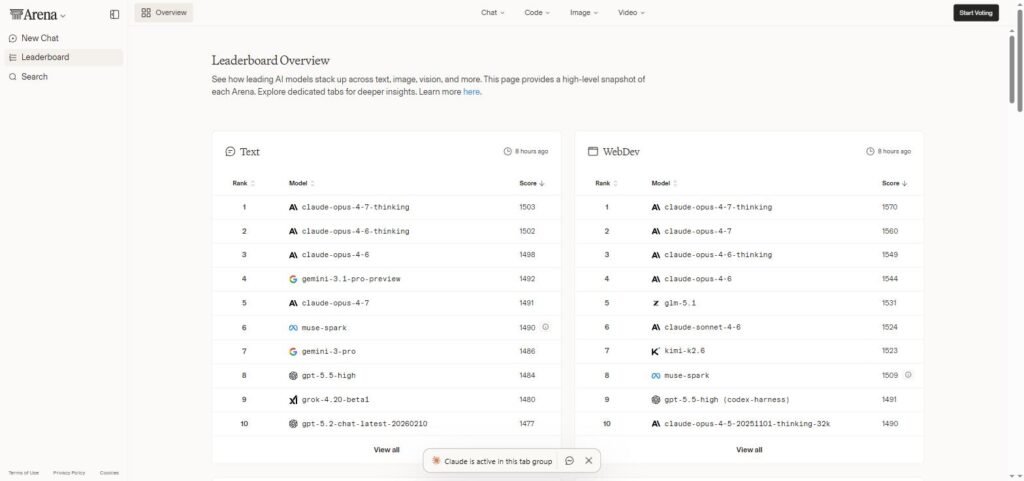
LMArena (anciennement LMSYS Chatbot Arena) est l’évaluation la plus utilisée par les chercheurs et les ingénieurs IA. Le principe est simple :
- Tu soumets un prompt sur lmarena.ai.
- Deux modèles répondent en aveugle — tu ne sais pas lesquels.
- Tu votes pour la meilleure réponse.
- Les votes alimentent un score Elo, comme aux échecs.
Au 6 mai 2026, LMArena a accumulé 6,1 millions de votes sur 357 modèles. C’est massif. Mais quatre biais structurels valent la peine d’être connus :
- Biais de longueur : les réponses longues gagnent plus souvent, indépendamment de la qualité réelle. Un modèle qui produit 500 mots score mieux qu’un modèle qui en produit 200, même quand le second est objectivement meilleur pour le prompt.
- Biais de style : les réponses bien formatées (titres, bullets, gras) battent souvent les réponses en prose pure. Les modèles entraînés à formater visuellement partent avec un avantage.
- Variance géographique : un même modèle ne classe pas pareil selon que les votes viennent majoritairement des USA, d’Inde ou d’Europe.
- Intervalles de confiance : le top 3 est très souvent à égalité statistique. La position n°1 affichée peut être trompeuse.
Pour une décision pro (signature de contrat, choix d’un modèle pour ton produit), ne te contente jamais de LMArena. Croise avec l’Artificial Analysis Intelligence Index v3 qui agrège 10 benchmarks — MMLU-Pro, Humanity’s Last Exam, GPQA Diamond, AIME, IFBench, SciCode, LiveCodeBench, Terminal-Bench Hard, AA-LCR, 𝜏²-Bench Telecom. Et fais surtout tes propres tests sur tes vrais prompts. Données disponibles sur artificialanalysis.ai.
Comment choisir la méthode de classement des modèles ?
Trois familles de classements coexistent en 2026, et chacune a ses limites.
- Préférence humaine (LMArena) : reflète l’expérience réelle de millions d’utilisateurs. Limite : biais de longueur, de style, et variance géographique.
- Benchmarks automatisés (MMLU, GPQA, SWE-Bench) : reproductibles et précis. Limite : « bachotables » — les éditeurs entraînent leurs modèles à les passer.
- Indices composites (AAII v3, LLM Stats Score) : agrègent plusieurs benchmarks pour une vue plus stable. Limite : la pondération est rarement transparente, et les choix de benchmarks orientent le résultat.
💡 Notre conseil : ne te fies jamais à un seul classement. Pour un usage perso, LMArena suffit pour avoir une intuition. Pour un usage pro, croise au minimum LMArena + 1 benchmark technique pertinent à ta tâche (SWE-Bench si tu codes, GPQA si tu fais du raisonnement, AAII si tu veux une vue large). Et fais tes tests sur tes prompts à toi.
Les modèles les plus appréciés sont-ils économes en énergie ?
Non. Les modèles top du classement sont les plus gourmands. Une requête sur Claude Opus 4.7 consomme entre 5 et 20× plus qu’une requête sur Sonnet 4.6, selon la complexité du prompt et le mode de pensée activé. Le passage à Opus 4.7 a même introduit un nouveau tokenizer qui peut augmenter le coût effectif de 0 à 35 % par requête à prix par token inchangé.
Si l’efficience énergétique compte pour toi (FinOps, RSE, simple bon sens), regarde plutôt :
- Claude Sonnet 4.6 (Anthropic) : 3 $/15 $ par million de tokens, couvre 90 % des usages courants.
- Gemini 2.5 Flash (Google) : ultra-rapide, faible empreinte, gratuit en version standard.
- DeepSeek V3 : un des meilleurs ratios performance/coût du marché, surtout en API.
- Kimi K2.6 : leader open-weights à environ 0,95 $ par million de tokens.
Règle pratique qu’on voit appliquée dans les boîtes qui gèrent leurs coûts IA sérieusement : un modèle léger pour 80 % des tâches, un top modèle réservé aux 20 % qui en ont vraiment besoin. C’est exactement ce que recommandent les guides FinOps publiés depuis le lancement d’Opus 4.7.
Quelles sont les 10 IA les plus connues du grand public ?
Si on classe par notoriété (recherches Google, présence média, enquêtes d’usage 2026), voici le top 10 grand public :
- ChatGPT (OpenAI)
- Gemini (Google, ex-Bard)
- Claude (Anthropic)
- Copilot (Microsoft)
- Grok (xAI)
- Perplexity
- DeepSeek
- Le Chat (Mistral)
- Meta AI (intégré WhatsApp et Instagram)
- Midjourney (image)
La notoriété n’est pas la qualité. Beaucoup de gens connaissent ChatGPT par cœur sans avoir jamais testé Claude. D’autres utilisent ia yahoo (l’assistant Yahoo lancé en 2025) ou Le Chat sans réaliser qu’ils ont accès, gratuitement, à des modèles compétitifs. Tester plusieurs IA pendant deux semaines révèle souvent des préférences inattendues.
Quels sont les 7 types d’IA ?
La typologie classique en informatique distingue sept catégories — quatre par capacité, trois par portée :
- IA réactive : aucune mémoire, répond uniquement au présent. Exemple historique : Deep Blue d’IBM aux échecs.
- IA à mémoire limitée : garde un contexte court. La majorité des LLM actuels (ChatGPT, Claude, Gemini) entrent ici.
- Théorie de l’esprit : capable de modéliser les états mentaux d’autrui. Toujours en recherche.
- IA conscience de soi : hypothétique. N’existe pas.
- ANI (Artificial Narrow Intelligence) : spécialisée sur une tâche. Siri, recommandations Netflix, filtres anti-spam.
- AGI (Artificial General Intelligence) : niveau humain sur toutes les tâches cognitives. Non atteinte officiellement, malgré les annonces marketing.
- ASI (Artificial Super Intelligence) : dépasse l’humain. Théorique.
En 2026, tous les modèles commerciaux — y compris les plus puissants comme Claude Opus 4.7 ou Mythos Preview — sont des ANI à mémoire limitée. Ils sont impressionnants sur certaines tâches, mais ne sont ni généraux, ni conscients d’eux-mêmes.
FAQ — Classement IA 2026
À quelle fréquence le classement IA change-t-il ?
Hebdomadairement sur LMArena. Mensuellement sur les benchmarks fermés. Les sorties majeures (Opus 4.7 le 16 avril 2026, GPT-5.4 plus tôt cette année) rebattent les cartes en quelques jours.
Quel modèle pour un usage gratuit ?
ChatGPT (GPT-5 limité), Gemini (2.5 Flash sans limites strictes), Le Chat de Mistral (généreux et hébergé en Europe), Claude (limité mais accessible). DeepSeek est gratuit en chat et très bon marché en API.
Faut-il payer pour un modèle premium ?
Pour un usage occasionnel, les versions gratuites couvrent largement 90 % des besoins. Pour un usage pro intensif (codage, écriture longue, agentic), oui — l’écart de qualité justifie 20 €/mois. ChatGPT Plus, Claude Pro et Gemini Advanced sont à ce prix.
Le classement IA est-il fiable pour choisir un outil pro ?
Comme repère, oui. Comme décision finale, non. Toujours faire un test interne sur tes prompts réels avant de signer un contrat annuel. Une équipe procurement qui choisit son LLM sur une capture LMArena d’un mardi peut perdre 15 à 20 % de sa facture sur l’année à cause d’un classement déjà obsolète le mardi suivant.
Quelle IA pour le français ?
Le Chat (Mistral) est conçu pour le français et hébergé en Europe. Claude Opus 4.7 et Gemini 3.1 Pro sont aussi excellents en français. ChatGPT est correct mais a parfois des tournures qui sentent la traduction de l’anglais.
🎯 Verdict : par où commencer
Si tu n’as pas le temps de tester : ChatGPT pour le quotidien, Claude Opus 4.7 dès que ça devient sérieux (code, analyse longue, raisonnement).
Si tu paies pour ton équipe : Claude Sonnet 4.6 en modèle par défaut, Opus 4.7 sur les 20 % de tâches lourdes, Gemini 2.5 Flash pour les requêtes massives à coût contraint.
Si tu cherches la souveraineté ou un budget serré : Le Chat (Mistral) pour le français hébergé en Europe, DeepSeek V3 pour le ratio qualité/prix imbattable.


